The interesting thing about GLM 5.2 is not just that it is another strong coding model. The interesting thing is that builders are starting to route it into the Claude Code harness and use it as a cheaper execution layer for real work.
That changes the decision from "Which model is best?" to "Which model should run this part of the workflow?" For a small team, that is the more useful question. Opus can stay on the work that needs the highest trust. GLM 5.2 can be tested on high-volume coding, audits, refactors, research, and project exploration where cost matters.
Source note
The video frames GLM 5.2 as a much cheaper Opus alternative inside Claude Code. That is useful as a builder report, but the source-backed facts in this post come from Z.AI's official GLM 5.2 documentation, the Z.AI Claude Code guide, the model-switching guide, the pricing page, and Anthropic's Opus 4.8 pricing note.
One thing I am intentionally careful about: the video description says GLM 5.2 is a 756 billion parameter open-source model. I did not find that exact parameter-count claim in the official Z.AI docs I could verify, so I am not using it as the factual spine. The safer confirmed point is that Z.AI positions GLM 5.2 as its flagship long-horizon coding model with 1M context and strong open-source-model benchmark performance.
What GLM 5.2 is
Z.AI describes GLM 5.2 as a flagship foundation model built for long-horizon tasks. The headline specs are straightforward:
- Input and output: text in, text out.
- Context length: 1M tokens.
- Maximum output: 128K tokens.
- Capabilities: thinking mode, streaming output, function calling, context caching, structured output, and MCP integration.
- Use cases: project-level codebase understanding, long-horizon refactoring, engineering-standards stress tests, mobile debugging loops, mini-program migration, game loops, research reproduction, and code-to-video workflows.
The part that matters for builders is not only the context number. Z.AI's own GLM 5.2 page makes the better point: long context only helps if the model can preserve project constraints and engineering decisions across the task. That is exactly what we should test.
A million-token window that forgets the point is just a bigger room to get lost in. A million-token window that keeps module boundaries, APIs, style rules, and tests in view is a real agent advantage.
Why Claude Code changes the story
Claude Code is not just a model picker. It is a harness: file access, shell commands, project memory, plans, edits, tests, and review loops. When you route another model through that harness, you are testing more than raw intelligence. You are testing whether the model can operate inside an agent workflow.
Z.AI's Claude Code guide says Claude Code can be configured to use Z.AI through an Anthropic-compatible base URL. It also notes that after setup, the Claude interface may still show Claude model names while the actual server-side model mapping uses GLM.
That is the practical twist. For day-to-day work, you can keep your Claude Code muscle memory and test GLM 5.2 behind it. Same harness, different engine.
Claude Code config
The video uses a project-local configuration. Keep this out of Git. Treat the API key like any other secret.
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.z.ai/api/anthropic",
"ANTHROPIC_AUTH_TOKEN": "your-z-ai-api-key-here",
"ANTHROPIC_API_KEY": "",
"API_TIMEOUT_MS": "3000000",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.2",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.2",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-5.2",
"ANTHROPIC_SMALL_FAST_MODEL": "glm-5.2",
"CLAUDE_CODE_SUBAGENT_MODEL": "glm-5.2"
}
}
Z.AI's official docs show a smaller base configuration with ANTHROPIC_AUTH_TOKEN, ANTHROPIC_BASE_URL, and API_TIMEOUT_MS. Their model-switching guide also shows this 1M-context variant:
{
"env": {
"CLAUDE_CODE_AUTO_COMPACT_WINDOW": "1000000",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.2[1m]",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.2[1m]"
}
}My practical recommendation: start with a project-local test, not a global swap. Pick one repo. Run the same task once with your usual model and once with GLM 5.2. Compare output quality, number of retries, test results, time, and cost.
.claude/settings.local.json if it contains a real API key. Add it to .gitignore and keep a redacted example if your team needs documentation.
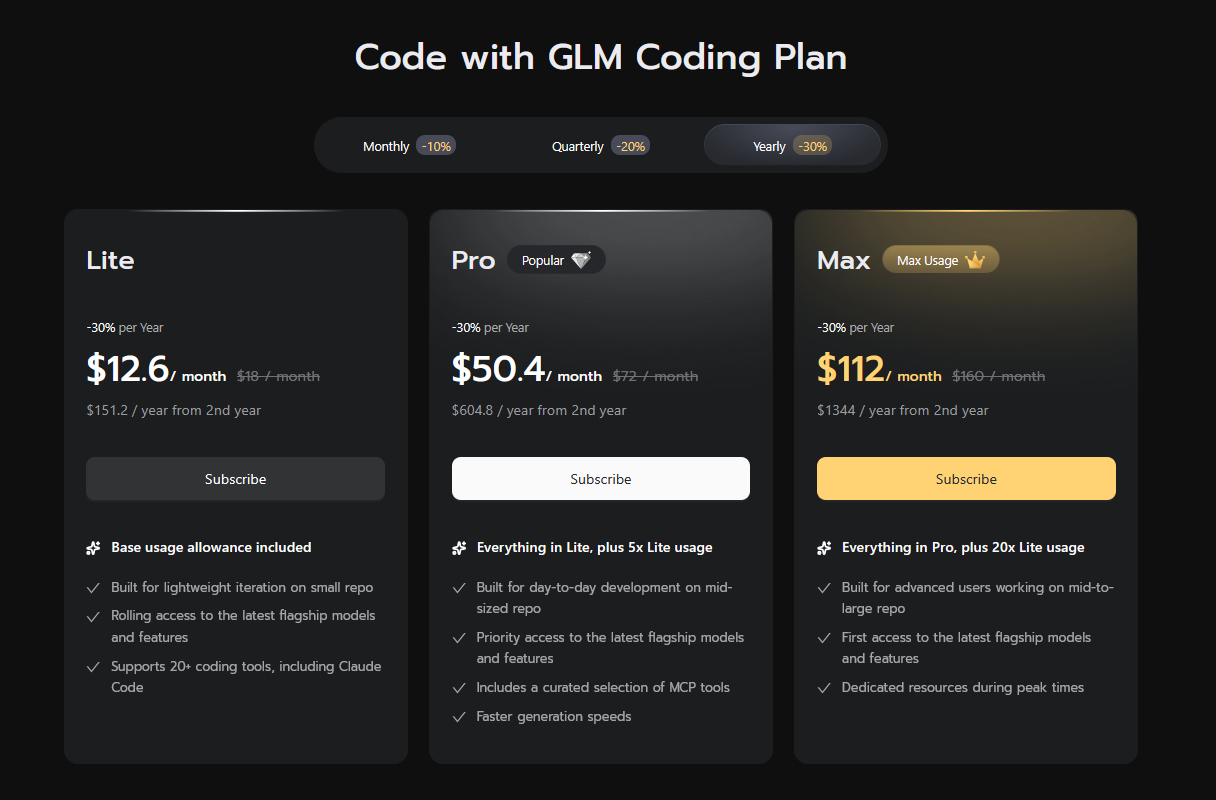
Cost and pricing reality
Z.AI's pricing page lists GLM 5.2 at $1.40 per 1M input tokens and $4.40 per 1M output tokens, with cached input listed at $0.26 per 1M tokens. Anthropic's Opus 4.8 release lists regular Opus pricing at $5 per 1M input tokens and $25 per 1M output tokens.
That makes GLM 5.2 materially cheaper on raw API token price. But the real metric is not token price. It is cost per accepted task.
A cheaper model is not cheaper if it needs three retries, skips tests, burns your context window, or forces a human to clean up the work. It is much cheaper if it completes the boring 80% with acceptable quality and leaves Opus for the scary 20%.
Z.AI also says its GLM Coding Plan supports GLM 5.2, GLM-5-Turbo, and GLM-4.7, with usage limits on 5-hour and weekly windows. Its docs recommend GLM 5.2 for complex tasks and GLM-4.7 for routine tasks to avoid burning quota too quickly.
Where I would route GLM 5.2
I would not start by asking whether GLM 5.2 beats Opus. I would start by asking which workflows deserve a cheaper, high-context model.
- Codebase maps: ask it to read a repo and produce architecture, module responsibilities, risks, and constraints.
- First-pass refactors: use it for scoped, test-backed cleanup where behavior must not change.
- Documentation work: README updates, implementation notes, API docs, migration notes, release drafts.
- Research inside repos: find where a feature lives, map dependencies, summarize old decisions, collect TODOs.
- Test generation: ask for focused tests around existing behavior before you change code.
- Subagent work: route parallel exploration tasks to GLM 5.2, then bring the final decision back to a stronger review model.
- Non-sensitive knowledge work: drafts, comparisons, cleanup, structured notes, and repetitive analysis.
This is where the economics get interesting. If GLM 5.2 is good enough for exploration, scaffolding, and routine implementation, you can save the expensive model for planning, final review, and the decisions where judgment matters.
Where Opus still belongs
The stronger and cheaper open models get, the more tempting it is to route everything away from Opus. I would resist that.
Keep Opus or your most trusted frontier model for:
- High-stakes production changes.
- Final security review before deployment.
- Complex architecture decisions with long-term consequences.
- Customer-facing copy where brand risk is high.
- Tasks involving private, regulated, financial, legal, or health-sensitive data.
- Debugging where a false explanation can waste hours.
- Final merge review after a cheaper model did the draft work.
This is not model loyalty. It is workflow design. Use the cheaper model where cost matters. Use the trusted model where mistakes are expensive.
Testing checklist
If you want to test GLM 5.2 in Claude Code, do it like a systems builder:
- Pick one repo. Do not switch your whole machine on day one.
- Use a project-local config. Keep API keys out of Git.
- Run a baseline task with Opus. Save the prompt, time, cost estimate, mistakes, and final output.
- Run the same task with GLM 5.2. Use the same acceptance criteria.
- Score the result. Did it pass tests? Did it respect scope? Did it over-edit? Did it explain tradeoffs?
- Track retries. Raw price matters less than accepted-task price.
- Check tool behavior. Watch shell commands, file edits, tests, and whether it follows your
CLAUDE.md. - Route by task type. Decide what GLM owns, what Opus reviews, and what a human must approve.
The future of Claude Code is not one model. It is a harness with model routing. GLM 5.2 makes that future feel a lot more practical.
Sources
- YouTube: GLM 5.2 in Claude Code is Blowing My Mind
- Z.AI official GLM 5.2 blog
- Z.AI docs: GLM 5.2
- Z.AI docs: Claude Code setup
- Z.AI docs: How to switch models
- Z.AI docs: pricing
- Z.AI GLM Coding Plan
- Anthropic: Claude Opus 4.8 release and pricing
- JQ AI SYSTEMS: The Latest Codex Updates and the Truth About Opus 4.8
- JQ AI SYSTEMS: Claude Code Study: Domain Expertise Beats Coding Experience