Anthropic's new Claude Code research report says the quiet part very clearly: AI coding agents do not make expertise irrelevant. They make the right expertise more valuable.
The study analyzed about 400,000 privacy-preserving Claude Code sessions from roughly 235,000 people between October 2025 and April 2026. The headline is not that everyone suddenly becomes a software engineer. The headline is sharper: people who understand the problem can steer Claude Code well enough that the agent handles much of the implementation.
That is a huge deal for consultants, founders, operators, designers, accountants, lawyers, researchers, and small teams. Coding syntax is no longer the only gate. But clear judgment still is.
What Anthropic Studied
Anthropic's report, Agentic coding and persistent returns to expertise, looks at real Claude Code usage rather than only benchmarks. It covers interactive sessions through Claude Code's CLI, claude.ai, and the Claude Code desktop app.
Anthropic classified sessions by work mode, who made decisions, apparent user expertise, occupation, and whether the session showed evidence of success or failure. The report is careful about its limits: it cannot know every real-world outcome, and many labels come from model-based classifiers. Still, the patterns are useful.
The report's core question is practical: as coding agents get better, who gets leverage from them? The answer is not "only programmers." It is "people who can define and evaluate the work."
The Division Of Labor: Humans Plan, Claude Executes
The most useful chart in the report is the division of labor. Anthropic finds that in a typical session, people make about 70% of the planning decisions, while Claude makes about 80% of the execution decisions.
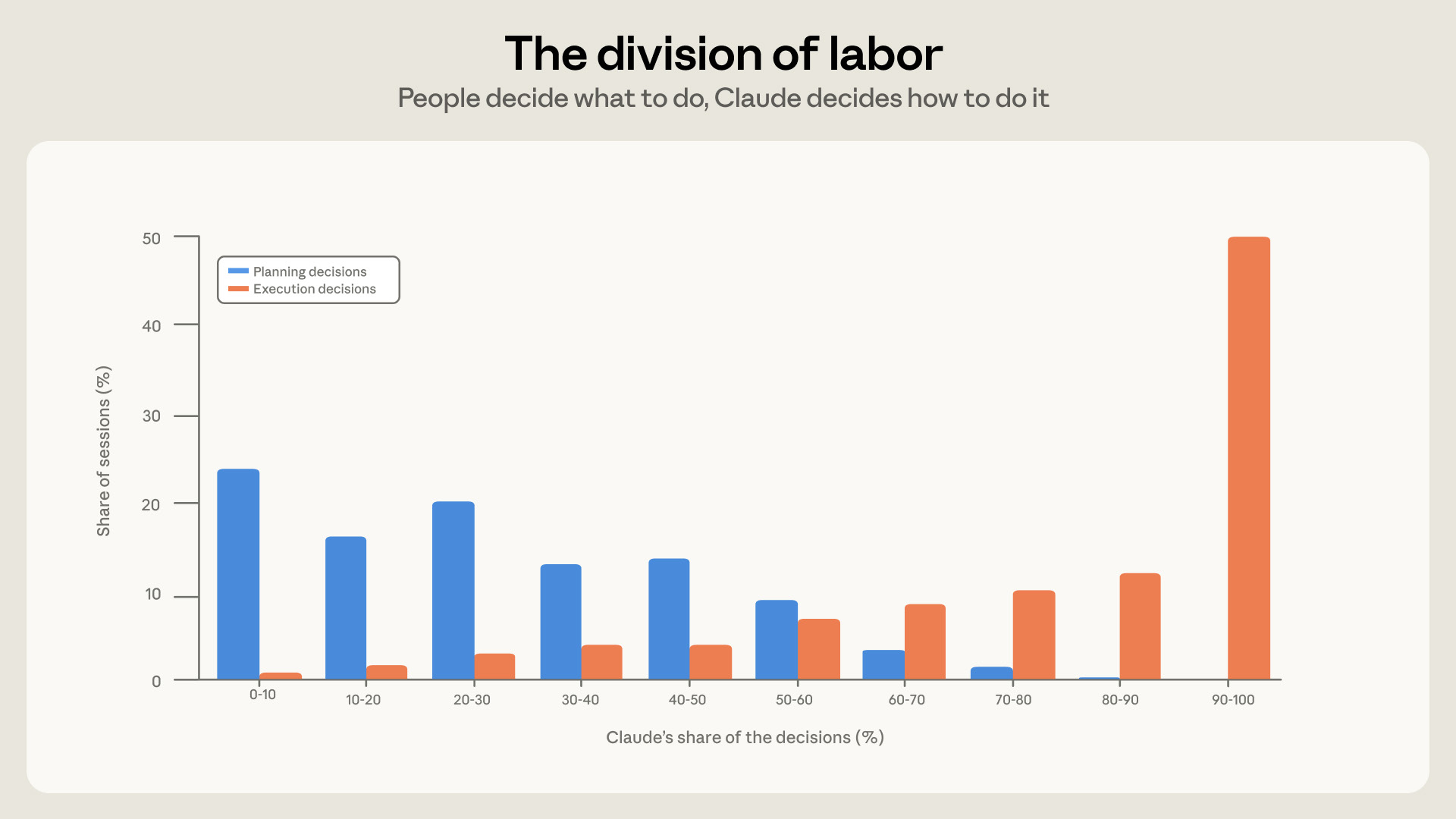
That maps almost perfectly to how good agent work feels in practice. The human decides the goal, the constraints, the examples, the edge cases, and what counts as finished. Claude decides which files to read, which code to write, which commands to run, and how to get through the implementation steps.
This is why vague prompts fail. If the human does not make the planning decisions well, Claude can still execute quickly, but it may execute the wrong thing.
The report also says that in historical data, each user prompt set off around 10 Claude actions on average, and sometimes more than 100. In each turn, Claude reads files, edits code, runs commands, and writes roughly 2,400 words of output on average. That is not autocomplete. That is delegated implementation.
Domain Expertise Beats Coding Experience
The strongest lesson for small businesses is this: domain expertise mattered more than traditional coding experience.
Anthropic gives a simple example in the report. A senior engineer asking their first Rust question may be a beginner at Rust. An accountant who has never used Python, but can explain the exact reconciliation rules and catch a month-end edge case, is an expert at that task.
That is the shift. Claude Code can supply a lot of implementation. But it cannot magically know the operational truth of your business unless you give it that truth.
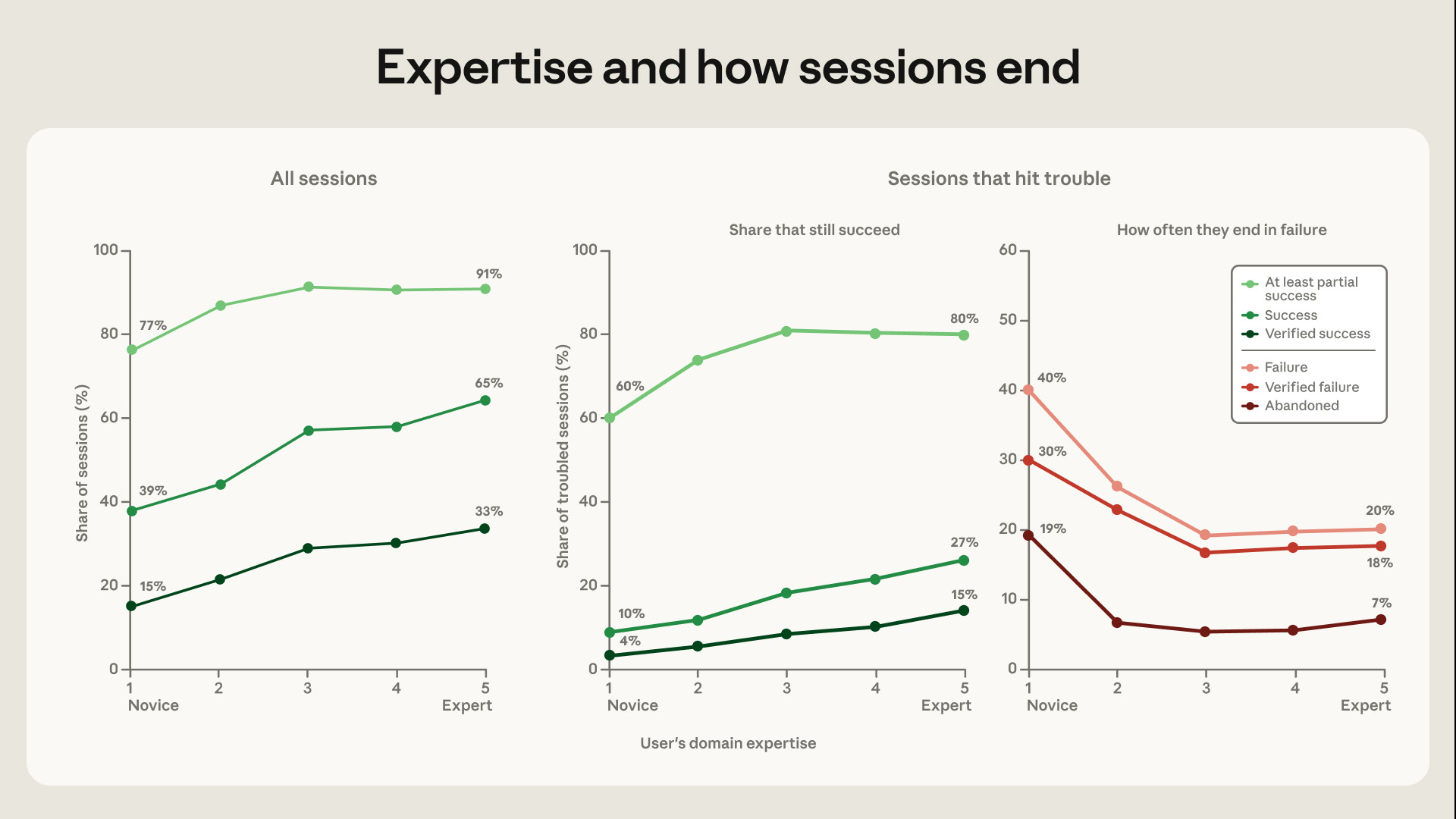
The numbers are blunt:
- Novice-rated sessions reached verified success 15% of the time.
- Intermediate and expert sessions reached verified success around 28% to 33% of the time.
- When sessions hit trouble, novice sessions were abandoned 19% of the time.
- For everyone else, abandonment was only about 5% to 7%.
The lesson is not that novices cannot use agents. It is that experts recover. They can spot wrong assumptions, correct the agent, narrow the task, and define a better verification path.
Why Experts Get More Work Per Prompt
Expert users did not just get better outputs. They also triggered more work from Claude per instruction.
Anthropic reports that typical novice sessions triggered about five Claude actions and roughly 600 output words per prompt. Expert sessions triggered about 12 actions and roughly 3,200 output words per prompt.
| User expertise | Claude actions per prompt | Output per prompt | What this means |
|---|---|---|---|
| Novice | ~5 actions | ~600 words | The prompt likely needs more clarification and narrower steering |
| Expert | ~12 actions | ~3,200 words | Claude can take a longer run because the instruction contains better judgment |
This is what I see in client work too. The best prompt is often not the most technical prompt. It is the prompt that says:
- Here is the real workflow.
- Here is what usually goes wrong.
- Here are the files and examples that matter.
- Here is what we must preserve.
- Here is how you should verify the result.
That is domain expertise turned into context. Once Claude has that, it can do a lot more between check-ins.
What Changed Over Seven Months
The report also shows Claude Code usage moving beyond "fix my bug."
Between October 2025 and April 2026, debugging fell from 33% to 19% of sessions. Meanwhile, operating software grew, and usage shifted toward deploying and running code, analyzing data, and writing non-code documents. Anthropic estimates the average task's economic value rose by about 27% over the seven months.
That matters because it shows Claude Code becoming a work surface, not just a coding helper. The agent is being used for implementation, data work, deployment, system operation, and documents around the work.
This matches the broader trend on the site: agents are moving from "write code" to "run a workflow." That is why memory, logs, permissions, review queues, and clear definitions of done are becoming more important.
What This Means For Small Teams
The best person to direct a Claude Code project is not always the best coder. Sometimes it is the person closest to the workflow.
A lawyer may be the right person to define a contract review tool. An accountant may be the right person to define a reconciliation script. A designer may be the right person to define a brand QA tool. A social media manager may be the right person to define a content pipeline. The implementer still matters, but the domain expert has become much more powerful.
For small teams, that changes the collaboration model:
- The domain expert defines the workflow, edge cases, examples, and acceptance criteria.
- The agent handles much of the implementation and iteration.
- A technical reviewer checks safety, structure, data handling, and deployment risk.
- The team keeps logs, tests, and examples so the workflow gets easier to repeat.
This is not "everyone is a developer now." It is more interesting than that. It is "people who deeply understand work can now shape software around that work."
A Better Prompting Checklist For Claude Code
If you want better AI coding results, do not start by learning more syntax. Start by explaining the domain, the edge cases, and what done means.
- State the business goal. What outcome should this create for the user or team?
- Name the source files and systems. What data, folders, APIs, reports, or examples matter?
- Explain the domain rules. What would an expert know that a generic coder would miss?
- List edge cases. What weird inputs, exceptions, customer cases, or month-end problems usually break the workflow?
- Define done. What visible result, passing test, generated file, dashboard, or user action proves the work is finished?
- Tell Claude what to verify. Should it run tests, compare before/after data, inspect output files, or check logs?
- Set review gates. What should never be shipped, sent, deleted, or changed without human review?
- Capture the lesson. If the workflow works, turn the prompt, examples, and review rules into a reusable skill or project memory.
The Anthropic study makes the future of coding agents feel less mystical. The agent can execute. The human still has to know what matters.
Sources
- Anthropic: Agentic coding and persistent returns to expertise
- Official Anthropic PDF report
- Local PDF copy supplied for drafting:
CCEconReport-H.pdf - JQ AI SYSTEMS: Safe Coding Agents Need Logs, Sandboxes, and Review Queues
- JQ AI SYSTEMS: Agent Memory Is Becoming the New Business Knowledge Base