Claude Fable 5 is not just "Claude Opus, but stronger." Anthropic is introducing a new public edge of the Claude family: a Mythos-class model that ordinary users can access, wrapped in safeguards that deliberately route some high-risk work away from Fable and back to Claude Opus 4.8.
That is the interesting part. Fable 5 is a capability release, a safety design, a pricing shift, and a workflow question at the same time. The builder question is not simply, "Is this the best model?" The better question is, "Which work is important enough, long enough, and hard enough to justify Fable?"
What Anthropic announced
Anthropic announced Claude Fable 5 and Claude Mythos 5 on June 9, 2026. The short version:
- Claude Fable 5 is a Mythos-class model made safe for general use.
- Claude Mythos 5 is the same underlying model with some safeguards lifted for restricted trusted-access use.
- Fable 5 is generally available on the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry.
- Mythos 5 is not generally available; it is limited to Project Glasswing partners and future trusted-access programs.
- Fable 5 and Mythos 5 use adaptive thinking, with 1M context and 128k max output according to Anthropic's model overview.
- Both models are priced at $10 per million input tokens and $50 per million output tokens.
Anthropic also says Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans from launch through June 22, 2026 at no extra cost, then moves to usage credits on June 23 unless capacity allows an extension. API and consumption-based Enterprise access are available from launch.
That makes this release unusual: it is powerful enough to need extra controls, but broad enough that builders can start testing it now.
Fable 5 vs Mythos 5
The naming is easy to trip over, so here is the clean version.
| Model | Who gets it | Safeguards | Best read |
|---|---|---|---|
| Claude Fable 5 | General users and developers | Robust safeguards; some flagged requests fall back to Opus 4.8 | The public Mythos-class model |
| Claude Mythos 5 | Project Glasswing and trusted-access users | Some safeguards lifted for approved defensive or research contexts | The restricted version of the same underlying model |
The model IDs make the distinction concrete: claude-fable-5 for the broadly available model and claude-mythos-5 for the restricted one.
This is the key design choice: Anthropic is trying to make Mythos-level capability broadly useful without broadly exposing the highest-risk parts of that capability.
Benchmarks in context
Anthropic's benchmark chart shows a large jump over Opus 4.8 in several areas, especially agentic coding, knowledge work, vision, legal, cybersecurity, and long-horizon terminal work. The chart is useful, but it should not become a religion.
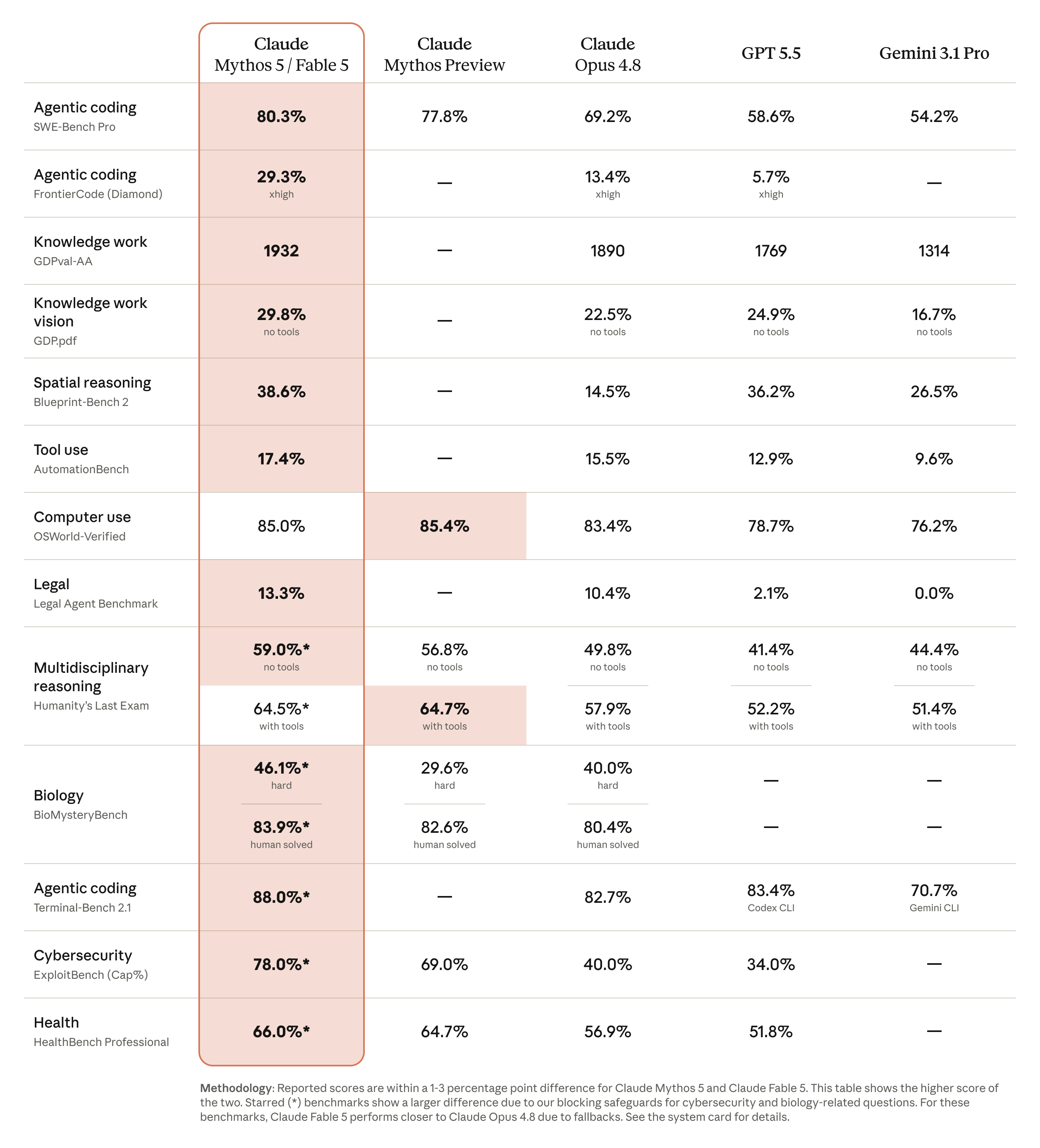
The chart highlights the shape of the release:
- Agentic coding: Anthropic reports 80.3% on SWE-Bench Pro for Mythos/Fable, compared with 69.2% for Opus 4.8.
- Frontier coding: 29.3% on FrontierCode Diamond at xhigh, compared with 13.4% for Opus 4.8.
- Knowledge work: 1932 on GDPval-AA, compared with 1890 for Opus 4.8.
- Vision-heavy knowledge work: 29.8% on GDP.pdf without tools, compared with 22.5% for Opus 4.8.
- Terminal coding: 88.0% on Terminal-Bench 2.1 in the table, compared with 82.7% for Opus 4.8.
- Computer use: Mythos Preview is slightly higher in the table, which is a good reminder that not every row is a clean sweep.
The practical reading is not "move every workflow immediately." It is: this model is probably worth testing where current models get tired, lose the thread, need too much scaffolding, or require too much step-by-step supervision.
The safeguard layer
The biggest product decision in Fable 5 is the fallback layer.
Anthropic says Fable 5 uses separate classifiers to detect potential misuse, including jailbreak attempts. When the classifiers detect requests related to cybersecurity, biology and chemistry, or distillation, the response is automatically handled by Claude Opus 4.8 instead. Users are informed when this happens.
This is more useful than a blunt refusal, because Opus 4.8 is still strong enough for many benign requests. Anthropic also says more than 95% of Fable sessions involve no fallback at all in early data.
If your workflow lives near cybersecurity, biology, chemistry, or model distillation, do not assume Fable 5 will behave like an unrestricted Mythos model. Design for fallback, false positives, and review.
There is another important operational detail: Anthropic says Fable 5, Mythos 5, and future models with similar or higher capability levels require 30-day retention for all traffic on Mythos-class models. Anthropic says this data is not used for training or non-safety purposes, but it is still a real data-handling constraint for sensitive business workflows.
So before using Fable 5 in a client system, ask: does this workflow allow 30-day retention? If not, Fable may be the wrong model even if it is the strongest one.
Pricing and when it is worth it
Fable 5 is expensive compared with Opus 4.8. Anthropic lists Fable 5 and Mythos 5 at $10 per million input tokens and $50 per million output tokens. Claude Opus 4.8 regular pricing is $5 per million input tokens and $25 per million output tokens.
That means the simple per-token price is double. But the real question is cost per completed task.
| Use Fable 5 when | Use Opus or another model when |
|---|---|
| The work is long, ambiguous, high-value, and failure is expensive. | The task is a quick edit, short answer, extraction, or routine draft. |
| You need multi-stage reasoning, self-checking, vision, files, and tool use. | The workflow already works reliably with a cheaper model. |
| Fewer turns, fewer retries, or better autonomy can offset the higher token price. | You cannot accept 30-day retention or domain fallbacks. |
The sweet spot is not "every prompt." It is the hard work you keep avoiding because current models need too many check-ins.
Long-horizon work: coding, research, finance, legal, vision
Anthropic's product page positions Fable 5 around ambitious, long-running projects. That is the right lens.
For JQ AI SYSTEMS readers, the strongest use cases are:
- Large coding migrations: refactors, framework upgrades, legacy cleanup, test generation, and multi-day implementation plans.
- Complex document work: finance packs, legal redlines, architecture documentation, PDFs with tables, and chart-heavy analysis.
- Research workflows: multi-source synthesis, hypothesis generation, evidence tables, literature maps, and long-running briefs.
- Vision-heavy build checks: comparing generated UI against screenshots, design goals, diagrams, and visual references.
- Agent harnesses: Claude Code or managed-agent workflows where the model can plan, delegate, test, and summarize progress.
The common ingredient is not intelligence in the abstract. It is staying with the problem. Fable 5 matters if it can keep track of the goal, use notes, inspect artifacts, check its own work, and return something a human can actually review.
What builders should test first
I would not switch production workflows blindly. I would run a small comparison set.
- Pick three hard tasks where Opus 4.8 struggled. Use real tasks, not novelty demos.
- Measure completed-task cost. Include retries, follow-up prompts, tool calls, and human review time.
- Test fallback behavior. Especially if your workflow touches security, biology, chemistry, or model training content.
- Check retention fit. Do not send sensitive client data if the 30-day retention requirement conflicts with your obligations.
- Keep review gates. Code, finance, legal, customer-facing copy, and production changes still need human approval.
- Log the difference. Note where Fable reduces steps, catches errors, asks better questions, or overbuilds.
Use Fable 5 for the work that justifies Mythos-class capability: long-horizon coding, deep research, complex documents, and reviewed agent workflows, not every everyday prompt.
Videos and official demos
The videos below are useful as launch context, demos, and commentary. I would treat the official Anthropic pages as the factual source, and the walkthrough videos as interpretation and early user framing.
Sources
This post uses Anthropic's release and model documentation as the factual spine. The supplied transcripts and requested videos are used as commentary and workflow inspiration, not as the primary confirmation layer.
- Anthropic: Claude Fable 5 and Claude Mythos 5
- Anthropic: Claude Fable 5 product page
- Anthropic: Claude Mythos 5 product page
- Claude API docs: Models overview
- Anthropic: Project Glasswing
- YouTube: Introducing Claude Fable 5
- YouTube: Fable 5 walkthrough video
- YouTube: Fable/Mythos analysis video
- YouTube: Additional Fable/Mythos video
- YouTube: Official Anthropic demo
- YouTube: Official Anthropic demo
- YouTube: Official Anthropic demo
The short version: Fable 5 is the model to test when the work is long, hard, and worth supervision. It is not the model to burn on every easy prompt. The frontier is moving from "can the model answer?" to "can the model stay with a serious project, stay inside guardrails, and produce something reviewable?"