Anthropic just dropped Claude Opus 4.8, and the useful story is not simply "new model, bigger benchmark chart." The useful story is that Opus is becoming a more controllable work engine for Claude Code, agent workflows, and production AI systems.
The release matters because it touches the parts builders actually feel: coding reliability, tool use, long-running work, rate limits, effort settings, progress honesty, and the ability to break large jobs into smaller reviewed pieces. That is where an AI model stops being a clever chat window and starts becoming a workflow component.
So yes, the benchmarks are strong. But the better question is: where should you actually use Opus 4.8, and where should you test before switching?
What Anthropic announced
Anthropic published Claude Opus 4.8 on 28 May 2026. The official framing is straightforward: Opus 4.8 builds on Opus 4.7, improves benchmark performance, and is a more effective collaborator for agentic work.
The practical release notes are the important part:
- Regular pricing is unchanged: $5 per million input tokens and $25 per million output tokens.
- Fast mode is cheaper than before: Anthropic says fast mode runs at 2.5x speed and is now three times cheaper than it was for previous models. Fast mode pricing is $10 per million input tokens and $50 per million output tokens.
- Availability is broad: Claude.ai, Claude Code, the Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
- Claude Code gets dynamic workflows: Claude can plan large tasks, run parallel subagents, verify outputs, and report back.
- Claude.ai gets effort control: users can decide how much effort Claude spends on a task.
- The Messages API gets a developer upgrade: system entries can now appear inside the messages array, which lets developers update instructions mid-task without breaking prompt cache.
That last point is easy to skip, but it matters for agent systems. If your agent needs to update permissions, token budgets, or environment context while it runs, the API now has a cleaner way to represent that change.
Benchmarks in context
Anthropic's benchmark table shows Opus 4.8 ahead of Opus 4.7 on most listed tests, and ahead of GPT-5.5 and Gemini 3.1 Pro on several of them. That is good signal, but it is not a blank cheque. One visible example: GPT-5.5 is higher on Terminal-Bench 2.1 in the table, so this is not a "wins everything" release.
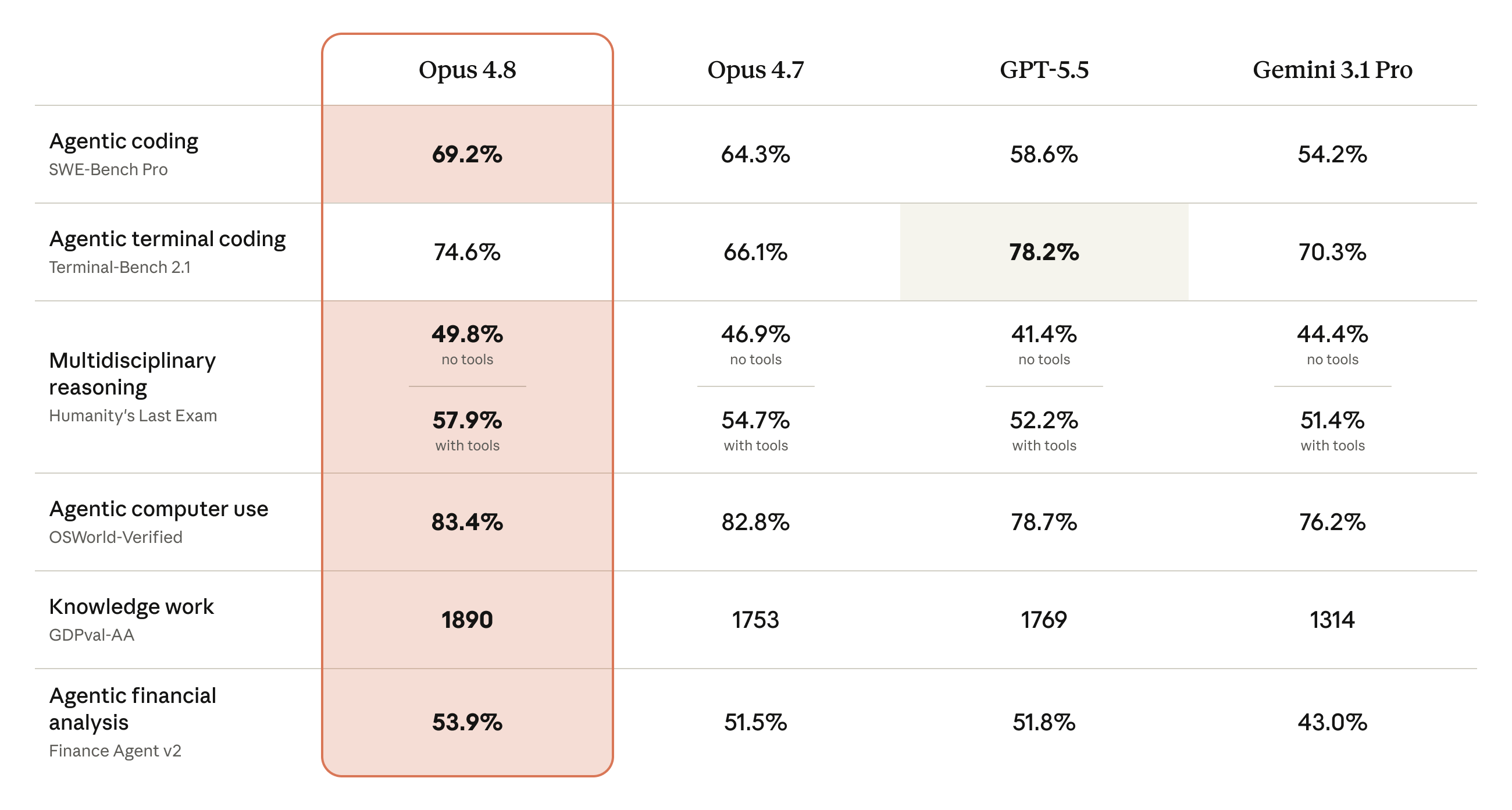
The numbers worth noticing for builders are not abstract IQ points. They map to the kinds of work Claude Code and agent systems already do:
- Agentic coding: 69.2% on SWE-Bench Pro, up from 64.3% for Opus 4.7.
- Agentic terminal coding: 74.6% on Terminal-Bench 2.1, up from 66.1% for Opus 4.7.
- Multidisciplinary reasoning: 49.8% on Humanity's Last Exam without tools, and 57.9% with tools.
- Agentic computer use: 83.4% on OSWorld-Verified.
- Knowledge work: 1890 on GDPval-AA.
- Agentic financial analysis: 53.9% on Finance Agent v2.
For JQ AI SYSTEMS work, the important categories are coding, computer use, and knowledge work. Those are the layers that show up in real automations: inspect a repo, modify a tool, read messy input, call services, write a draft, check the result, and hand it to a human reviewer.
The honesty upgrade
The most interesting part of Opus 4.8 may be the least flashy: Anthropic says the model is more honest about its own progress and more likely to flag uncertainty. That matters because long-running agents do not fail only by producing wrong answers. They also fail by saying "done" when they are not done.
Anthropic says Opus 4.8 is around four times less likely than Opus 4.7 to let flaws in code it has written pass unremarked. The company also reports substantially lower rates of misaligned behavior than Opus 4.7, similar to Claude Mythos Preview.
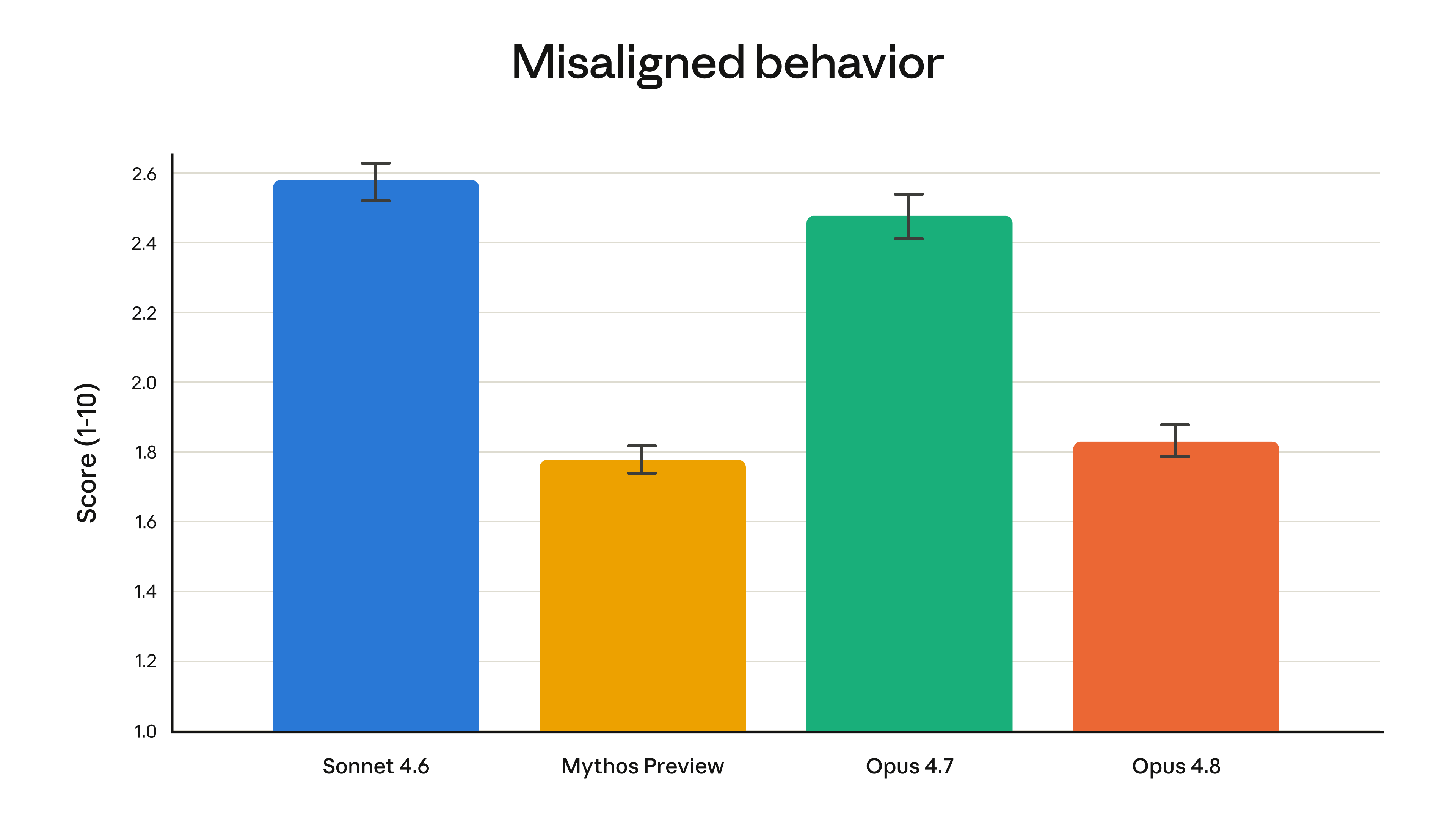
This is the part I would watch in real usage. If Opus 4.8 is better at saying "I found a problem," "I have not finished," or "this needs review," that is a meaningful improvement for code agents, finance workflows, client-facing reports, and anything with approval gates.
Effort levels as a workflow lever
The everyday workflow change is effort control. Anthropic says Opus 4.8 defaults to high effort, which it sees as the best balance of quality and user experience. Users can also choose extra, called xhigh in Claude Code, or max for harder work.
That turns "which model should I use?" into a slightly better question: how much effort should this task deserve?
Too much effort
- Simple edits become slower.
- The model may overthink small tasks.
- Token usage rises without much benefit.
- You burn limits on work that did not need it.
Right-sized effort
- Low or medium for small edits and lookups.
- High for normal coding and analysis.
- Extra for difficult tasks and async workflows.
- Max for large refactors, migrations, and deep review.
The two commentary videos embedded below make a similar practical point: if you open Claude Code and never touch the model or effort settings, you are leaving control on the table. The answer is not always "more effort." Sometimes the right move is lower effort, clearer context, and a narrower task.
Dynamic workflows in Claude Code
Dynamic workflows are the feature that makes Opus 4.8 feel less like a single-response model update and more like an agent architecture update. Anthropic says Claude Code can now plan larger tasks, run hundreds of parallel subagents in a single session, verify outputs, and report back.
In plain English: Claude can split a big job into smaller jobs, send those jobs out in parallel, then check what came back before handing you the final result.
That is useful for:
- Codebase-scale migrations where many files need consistent changes.
- Large refactors that require tests, docs, and regression checks.
- Bug sweeps across related modules.
- Feature implementation where frontend, backend, copy, and tests all need to move together.
- Audit work where the model needs to inspect multiple parts of a system before recommending changes.
The caution is obvious: parallel subagents do not remove the need for a control plane. They make review more important. If Claude touches more of your codebase, the workflow needs clearer tests, logs, permissions, branch discipline, and human approval before merge.
That is why this release connects directly to the /goal primitive. The next step in agent work is not only "let it run longer." It is "define done, verify done, and make the review path clear."
Videos and walkthroughs
Start with Anthropic's official video. It is the cleanest source for understanding dynamic workflows as a Claude Code feature, especially for long-running coding tasks.
Alex Finn's walkthrough is more enthusiastic and benchmark-heavy. It is useful as a builder reaction, especially for the Claude Code workflow angle, but I would treat claims about hidden changes, compute deals, and Mythos speculation as commentary rather than confirmed release facts.
Nate Herk's analysis is the more practical "how should you use it?" companion. The strongest takeaway is simple: benchmarks are not your workflow. Test effort levels, prompts, and context strategy against the work you actually do.
Switch-over checklist
If you use Claude for real work, I would not switch everything blindly. I would run a small, boring test plan first.
- Pick three tasks where Opus 4.7 frustrated you. Maybe it stopped too early, overexplained, missed a test, or claimed progress too soon.
- Run the same tasks in Opus 4.8. Keep the prompt, files, and acceptance criteria as similar as possible.
- Test effort levels deliberately. Try high, extra, and max only where the task justifies it. Try lower effort for small edits.
- Watch token usage and rate limits. A smarter model can still be the wrong choice if it burns too much context on routine work.
- Update prompts with context and reasons. Tell it what to do, what good looks like, and why the constraint exists.
- Keep review gates. For code, finance, customer-facing copy, and production systems, Opus 4.8 still needs tests and human approval.
- Log what changed. If 4.8 fixes a workflow, record the settings and prompt pattern so it becomes reusable.
This is the same deployment logic I use for client systems. The model can improve overnight, but the workflow still needs a map: inputs, rules, tools, review, and a clear definition of done.
CTA: Before switching production workflows to Opus 4.8, run your evals, choose the right effort level, and test the workflows where Opus 4.7 frustrated you.
Sources and videos
- Anthropic: Introducing Claude Opus 4.8
- Anthropic: Claude Opus 4.8 System Card
- Claude: Embrace long-running tasks with Opus 4.8 and Claude Code
- Alex Finn: Claude Opus 4.8 actually blew my mind
- Nate Herk: Opus 4.8 Just Dropped. Here's How To Actually Use It.
If your team is building AI agents for real workflows, the lesson is bigger than one model release. Better models help. But the durable advantage is the system around the model: task selection, context, effort level, permissions, tests, logs, review, and a clean handoff back to a human.